Cryptography Guide For UTAR Students
Cryptography Overview
Nowadays, cryptography challenges in CTF competitions have become more difficult and more common. Unlike Web and binary challenges, cryptography tests participants’ foundational knowledge and requires strong mathematical skills, logical thinking and analytical abilities. Cryptography challenges are varied such as:
- Statistical Analysis:
- Participants are given a large number of ciphertexts generated by a specific cryptosystem. The challenge is to analyze these ciphertexts using statistical methods to uncover patterns and deduce the plaintext.
- Custom Cryptosystems:
- Some challenges involve custom-designed cryptosystems with inherent weaknesses. The task is to identify these vulnerabilities, exploit them and recover the original plaintext.
- Interactive Interfaces:
- In some scenarios, participants are provided with an interactive interface to a weak encryption or decryption system. The goal is to exploit the system’s flaws to reveal sensitive information such as encryption keys or hidden messages.
Useful Tools for Cryptography
- Cyberchef
- RsaCtfTool
- Cipher Identifier
- Symbols Cipher Identifier
- Dcode
- QuipQuip
- factordb
- Crackstation
- SageMath Online
- Hash-Identifier
- Morse Code Translator
- DTMF tones decoder
Basics of Encoding
Encoding is a concept in computing that involves transforming information into a specific format for easier transmission, storage or processing. Unlike encryption, encoding is not meant to hide information, it simply formats it in a way that is compatible with various systems and technologies.
Common Encoding Methods in CTF
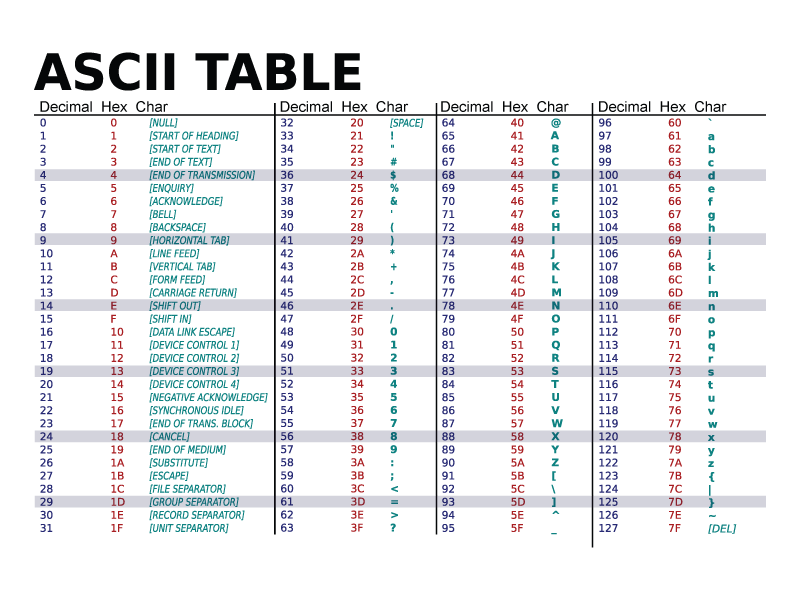
- ASCII (American Standard Code for Information Interchange)
- Purpose: ASCII is one of the most widely used encoding systems, especially in text processing and the internet.
- Content: It includes uppercase and lowercase letters, numbers and common punctuation marks. ASCII ensures that text can be universally understood across different systems and platforms.
- Morse Code
- History: Morse code was an early telecommunication method used for sending messages over long distances via telegraph.
- Structure:
- Dot (•): The basic unit of Morse code.
- Dash (―): Equivalent to the length of three dots.
- Intra-character Spacing: The space between dots and dashes within the same character is the length of one dot.
- Inter-character Spacing: The space between different characters (letters or digits) is the length of three dots.
- Word Spacing: The space between words is the length of seven dots.
- Purpose: Morse code converts written characters into signals, making it easier to transmit messages over telegraph systems.

Common Base Encoding and Other Encodings in CTF
No need to memorize, just need to be familiar on how they looked:
- Base64
- Uses a set of 64 characters: A-Z, a-z, 0-9, +, and /.
- Usually when you see
==at the end of the string, 90% of the time it isbase64. Normal text: ctf{base64_encoding},Base64encoded text: Y3Rme2Jhc2U2NF9lbmNvZGluZ30=
- Base32
- Uses A-Z and 2-7, totaling
32characters. Normal text: ctf{base32_encoding},Base32encoded text: MN2GM63CMFZWKMZSL5SW4Y3PMRUW4Z35
- Uses A-Z and 2-7, totaling
- Base16
- Uses A-F and 0-9, totaling 16 characters.
- It is also known as
Hex (Hexadecimal). Normal text: ctf{base16_encoding},Base16encoded text: 63 74 66 7b 62 61 73 65 31 36 5f 65 6e 63 6f 64 69 6e 67 7d.
- Base65536
- You may read more about it here
Normal text: ctf{base65536_encoding},Base65536encoded text: 𓉣𠅦院驳樶栵鐶𐙥𒁣鹤鱮ᕽ
- Octal
- Uses 0-7, totaling 8 characters.
Normal text: ctf{random_text},Octalencoded text: 143 164 146 173 162 141 156 144 157 155 137 164 145 170 164 175.
- Decimal
- Uses 0-9, totalling 10 characters.
Normal text: ctf{decimal},Decimalencoded text: 99 116 102 123 100 101 99 105 109 97 108 125.
- Binary
- Uses 0-1, totaling 2 characters
Normal text: ctf{binary},Binaryencoded text: 01100011 01110100 01100110 01111011 01100010 01101001 01101110 01100001 01110010 01111001 01111101.
- Letter Numbers
- Basically using
lettersasnumbers. - Example: A = 1, B = 2, C = 3 and so on.
- Basically using
- xxencode
- Similar to
base64but uses a different conversion table. - Usually when you see
++at the end of the string, it is most likelyxxencode. Normal text: ctf{xxencode_encoding},xxencodeencoded text: KMrFaSrVsNKtXPqFZLqJiMqxYOKtbTE++
- Similar to
- URL Encoding
- If a character has a special meaning in a URL context (e.g.,
/as a path delimiter), its ASCII code is represented as two hexadecimal digits, preceded by%. For example,/is encoded as%2For%2fwhen it needs to appear in a URL without being interpreted as a path delimiter. Non-ASCII characters are first converted to UTF-8, and then each byte is encoded in the same way. Normal text: https://sampleurlencoding.com,URLencoded text: https%3A%2F%2Fsampleurlencoding.com
- If a character has a special meaning in a URL context (e.g.,
- jjencode and aaencode
- jjencode and aaencode are encoding methods used to obfuscate JavaScript code
- jjencode: Encodes JavaScript code into strings composed only of symbols.
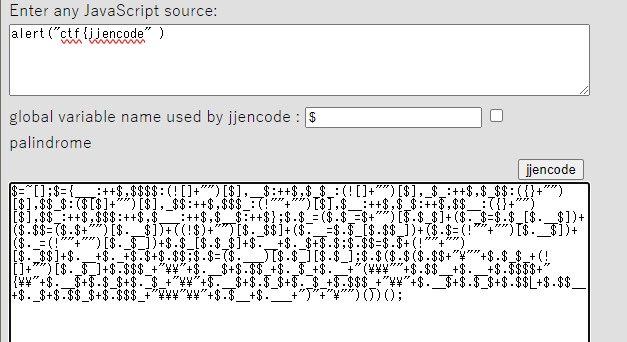 jjencode example
jjencode example- aaencode: Encodes JavaScript code into strings using common emoticons.
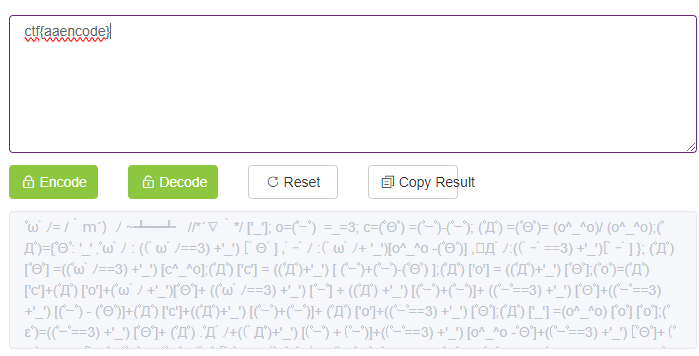 aaencode example
aaencode example
- jjencode and aaencode are encoding methods used to obfuscate JavaScript code
Classical Ciphers in CTF
In short, classical ciphers is where encryption of plain text is done by using substitution and / or shift. Nowadays, it is rarely used because it is very easy to crack.
Caesar Cipher | ROT13
The Caesar Cipher is one of the simplest and most well-known classical encryption techniques. It is a substitution cipher where each letter in the plaintext is replaced by a letter a fixed number of positions forward (or backward) in the alphabet. For example, with an offset of 3, A becomes D, B becomes E and so on.
The encryption and decryption formulas for the Caesar Cipher are as follows, where x represents the plaintext character and n is the key (offset):
 Caesar Cipher Formula
Caesar Cipher Formula
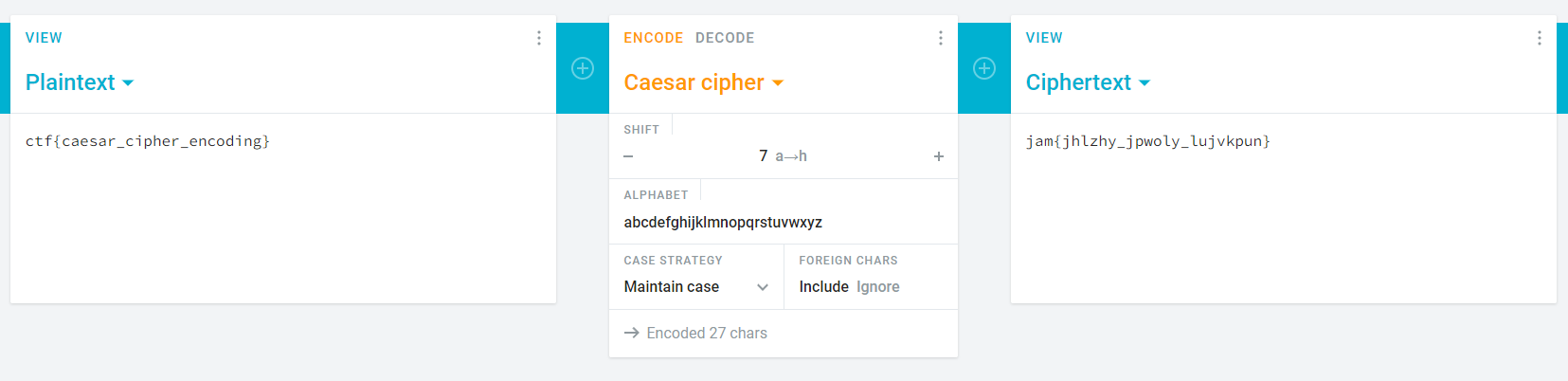 Caesar Cipher Example
Caesar Cipher Example
The Caesar Cipher is very easy to break even with a ciphertext-only attack. If you know that a Caesar Cipher is used but don’t know the offset, you can crack it using a brute-force approach as there are only 25 possible offsets (since an offset of 26 equals no transformation).
Note: Caesar cipher with key 13 is called ROT13.
Vigenère Cipher
Basically, for this cipher, you would need a plaintext and a key. Very similar to caesar cipher so be wary of that.
In a Vigenère Cipher, the key is repeated to match the length of the plaintext. For example, if the plaintext is VIGENERECIPHER and the key is CTF, the key is repeated to form CTFCTFCTFCTFCT. Each letter in the plaintext is then shifted by the offset corresponding to the matching letter in the key.
- Plaintext:
VIGENERECIPHER - Key:
CTFCTFCTFCTFCT - Ciphertext:
XBLGGJTXHKIMGK
The encryption is done by shifting each letter of the plaintext by the position of the corresponding letter in the key. For example:
Vis shifted byC(which is the 3rd letter of the alphabet, so the offset is 3 - 1 = 2), resulting inX.Iis shifted byT(which is the 20th letter of the alphabet, so the offset is 20 - 1 = 19), resulting inB.- And so on, resulting in the final ciphertext
XBLGGJTXHKIMGK.
If you are still a bit confused, you may refer to this 2 minutes video.
Bacon's Cipher
The Bacon Cipher is a method of steganography that encodes a message by replacing each letter of the plaintext with a group of five characters, either ‘A’ or ‘B’. This replacement is based on a 5-bit binary encoding system, where each letter of the alphabet is assigned a unique combination of five ‘A’s and ‘B’s. The Baconian cipher alphabet is typically structured as follows:
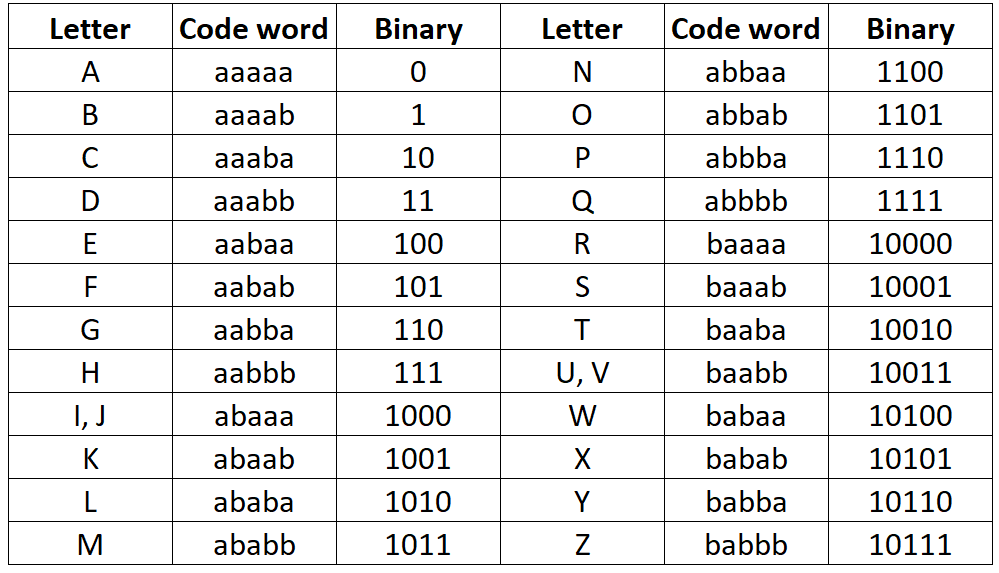
Example:
1
2
3
4
5
H -> AABBB
E -> AABAA
L -> ABABA
L -> ABABA
O -> ABBAB
So, “HELLO” in the Bacon Cipher would be encoded as AABBBAABAAABABAABABAABBAB.
Pigpen Cipher
The Pigpen Cipher is a simple substitution cipher where each letter of the alphabet is substituted with a symbol from a grid. The grid is typically divided into two parts, each containing a set of lines and dots that represent the letters of the alphabet. Here’s how the grid is generally structured:
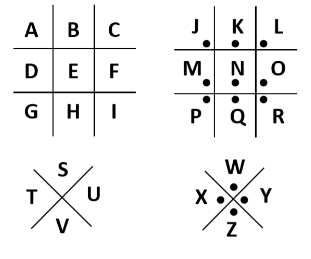
Example:
Rail Fence Cipher
In short, this cipher “moves” up and down on the “rails” to scatter the letters.
Encryption:
- Choose the number of rails (let’s say 3 for this example).
- Write the plaintext
diagonallyacross the rails, thenmove back upwhen you reach the bottom rail. - Once all the letters are placed, read each rail
line by lineto form the ciphertext.
Example:
- Plaintext:
WEAREDISCOVERED - Rails (in this case we chose 3):
1 2 3
W . . . E . . . C . . . R . . . E . R . D . S . O . E . E . . . A . . . I . . . V . . . D .
- Ciphertext:
WECRERDSOEEAIVD
Public Key Cryptography
Usually, easy RSA challenges are able to be solved using ChatGPT.
RSA is one of the most widely used cryptographic algorithms in modern times. The security of RSA is based on a simple mathematical principle: it is easy to compute n = p * q for large prime numbers p and q, but difficult to factorize n to retrieve p and q.
Basics of RSA
The basic steps of the RSA algorithm are as follows:
Select Two Large Primes: Choose two large prime numbers,
\[n = p \cdot q\]pandqand each typically greater than 512 bits, and calculate their product (multiply):Calculate Euler’s Totient Function which is:
\[ϕ(pq) = (p−1) \cdot (q−1)\]Choose a Public Exponent: Select an integer
ethat is co-prime withϕ(n), meaninggcd(e,ϕ(n)) = 1. Typically,eis chosen as asmallprime number such as65537.Calculate the Private Key: Compute
\[e \cdot d \equiv 1 \pmod{\phi(n)}\]d, the multiplicative inverse ofemoduloϕ(n):
The public key is (n,e) and the private key is (n,d).
Encryption and decryption are performed as follows:
Encryption: Given a plaintext message
\[c = m^e \mod n\]m, the ciphertextcis computed as:Decryption: Given the ciphertext
\[m = c^d \mod n\]c, the plaintextmis recovered by:
Solving RSA Challenges
In CTFs, RSA-related challenges typically provide participants with the public key or the encryption script used to encrypt a message, along with the ciphertext. The task is to calculate the correct plaintext using the given information.
RSA challenges often require handling high-precision arithmetic with large integers, which can be cumbersome in some programming languages. For this reason, it is recommended to write scripts in Python and use libraries like gmpy2 or SageMath.
In this section, we will be only introducing the basic RSA attacks so that you may get a better understanding on the theory behind each attacks. Some good tools include RsaCtfTool.
Factorization Attack on RSA
If the modulus n is not too large (typically less than or equal to 512 bits), it is possible to attempt factorization using modern computational tools such as factor-db.
For example, given the public key n = 510143758735509025530880200653196460532653147 and e = 65537, we can go to factor-db to factorize the n to get p and q.
You will get two numbers which 19704762736204164635843 and 25889363174021185185929.
The private key d can be calculated using gmpy2:
1
2
3
4
5
6
7
8
9
10
11
import gmpy2
p = 19704762736204164635843
q = 25889363174021185185929
n = p * q
e = 65537
phi = (p - 1) * (q - 1)
d = gmpy2.invert(e, phi)
print(d)
# output: 415660872067953163164640388695707122274867825
Small Plaintext and Low Exponent
When the plaintext m is small enough such that me < n, you can directly recover the plaintext by taking the e-th root of the ciphertext.
Example:
- n = 100000000000000000000000
- e = 3
- m = 200
The ciphertext c is calculated as:
Since c < n, the plaintext can be recovered by calculating the cube root of 8000000 which is 200.
When the ciphertext c is larger than n, but not excessively large, the ciphertext can be expressed as:
This can also be written as:
\[m^e = kn + c\]Where k is an integer cofficient. To recover the plaintext, you can enumerate possible values of k and check if the e-th root of kn + c is an integer.
Example taken from SKRCTF: Small-E 2:
- n = 91916062929755899991419452098776070211257414596875218275380603377591870182603435387592799597601677412725463330022618304491967226095274532701595395513081487786880774375261242719962843053332094817389705801521607097644046054957895718424075514672164946208067840011762933432075645942010887315772486354077753098921
- e = 5
- c = 35783243553484273090677089927059990920007599084499143586613182895028518498096602289698991044152216674632952484103049422671044257404009588038522559515118720479025871564218557941067601815602070912535220611164761904849438827907551620715608094645194620571566118891025017218047159723272277310954299826359459603893
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import gmpy2
from Crypto.Util.number import long_to_bytes
n = 91916062929755899991419452098776070211257414596875218275380603377591870182603435387592799597601677412725463330022618304491967226095274532701595395513081487786880774375261242719962843053332094817389705801521607097644046054957895718424075514672164946208067840011762933432075645942010887315772486354077753098921
e = 5
c = 35783243553484273090677089927059990920007599084499143586613182895028518498096602289698991044152216674632952484103049422671044257404009588038522559515118720479025871564218557941067601815602070912535220611164761904849438827907551620715608094645194620571566118891025017218047159723272277310954299826359459603893
k = 0
while gmpy2.iroot(c + k * n, e)[1] == False:
k += 1
print("k =", k)
print("cube root integer =", c + k * n)
print("plaintext =", gmpy2.iroot(c + k * n, e)[0])
# if you want to convert to a string
print(long_to_bytes(133848662737273283723912271384785165899077558871995298013511680))
# k = 467
# cube root integer = 42960584631749489569083561220055484779577220215825226078189354960230431893773900928295536403124135568417424327604665797620419738843897216359683572264124173516952347504811218908163715307721690350633527829921755276504618946493244852124758873446546224499739247404384314929997373814642356653776705427180670156800000
# plaintext = 133848662737273283723912271384785165899077558871995298013511680
# SKR{17_St1ll_t00_5m411}
So, when k = 467, the expression c + k * n yields an integer cube root and we find the plaintext.
Common Modulus Attack
In certain situations, an RSA cryptosystem might use the same modulus n but different public exponents e1 and e2 to encrypt the same plaintext m. If the exponents e1 and e2 are co-prime (eg: their GCD = 1), then it is possible to recover the plaintext m without knowing the private key.
First, solve the equation below for integers x and y using the Extended Euclidean Algorithm. This step is possible because e1 and e2 are co-prime as we mentioned earlier.
After that, using the values of x and y found above, calculate using the equation below to get the plaintext:
For example, consider the challenge taken from Asian Cyber Security Challenge (ACSC) 2021 named RSA Stream:
- n = 30004084769852356813752671105440339608383648259855991408799224369989221653141334011858388637782175392790629156827256797420595802457583565986882788667881921499468599322171673433298609987641468458633972069634856384101309327514278697390639738321868622386439249269795058985584353709739777081110979765232599757976759602245965314332404529910828253037394397471102918877473504943490285635862702543408002577628022054766664695619542702081689509713681170425764579507127909155563775027797744930354455708003402706090094588522963730499563711811899945647475596034599946875728770617584380135377604299815872040514361551864698426189453
- e1 = 65537
- e2 = 65539
- c1 = 530489626185248785056851529495092783240974579373830040400135117998066147498584282005309496586285271385506231683106346724399536589882147677475443005358465570312018463021023380158875601171041119440475590494900401582643123591578282709561956760477014082159052783432953072656108109476273394944336635577831111042479694270028769874796026950640461365001794257764912763201380626496424082849888995279082607284985523670452656614243517827527666302856674758359298101361902172718436672098102087255751052784491318925254694362060267194166375635365441545393480159914698549784337629720890519448049478918084785289492116323551062547228
- c2 = 1975203020409124908090102805292253341153118000694914516585327724068656268378954127150458523025431644302618409392088176708577321340935694848413811050189138250604932233209407629187417581011490944602128787989061600688049167723157190856755216866030081441779638063158285315586348531096003923657421804826633178796609646683752818371577683682492408250734361651757171442240970926919981163473448896903527190572762083777393917434735180310738365358292823914890490673423902906595054472069189915195457783207514064622885302504323568255100411042585986749851978474243733470017361089849160420069533504193247479827752630064951864510821
Use the Extended Euclidean Algorithm to find x and y such that:
1
2
3
g, x, y = gmpy2.gcdext(e1, e2)
print(x, y)
# (32769, -32768)
After that compute this:
\[c_1^x \cdot c_2^y \mod n\]1
2
3
4
5
m = pow(c1, x, n) * pow(c2, y, n) % n
print(m)
print(long_to_bytes(m))
# 32182379453737289502527295382960026291854481111868051493798884374879754956032315610400900449714999242868092886202368570210715401699910990511950223075854496431610452941002124016460408448404595858472812311891338885898619495609979631297307630576754392276991520591134394027073721531462902568388161017797437914305425299419706872217541376706184874627527668244488911103877643398280372567450398439486470381784163610492943882979013720082534669878346784033340322850427285731299973557496511465425434009977865274905164380639225358108502161486247891979867991330089472177322213877919600646564783831489753863975927752317068025502
# ACSC{changing_e_is_too_bad_idea_1119332842ed9c60c9917165c57dbd7072b016d5b683b67aba6a648456db189c}
Hence, in CTF, if you find the challenges only have one plaintext but have multiple e, try common modulus attack.
Håstad's Broadcast Attack
Håstad’s Broadcast Attack takes advantage of a situation where the same plaintext m is encrypted with the same public exponent e but using different moduli n1, n2, n3…, ni. If the number of ciphertexts i is greater than or equal to the public exponent e, the plaintext can be recovered without the need for decryption.
Let’s say we have the following:
\[c_1 = m^e \mod n_1 \] \[ c_2 = m^e \mod n_2 \] \[ c_3 = m^e \mod n_3 \] \[ \ldots \] \[ c_i = m^e \mod n_i\]Using the Chinese Remainder Theorem (CRT), we can combine these ciphertexts into a single value ci that satisfies:
\[c_i \equiv m^e \mod [n_i * n_2 * n_3 \dots]\]Also, it is important that m < ni. If m were larger than any of the moduli, the method would not yield the exact message after decryption.
For example, we have the following challenge from foreverctf named broadcoast:
- e = 3
- n1 = 92654857070767571890017042106637703986449117869087364338047922606069735162919
- c1 = 74597365847504917912916866838569123286395165031450770943853702985527537374325
- n2 = 98572474388371800971130449337009030864118807314878868777502700832091542642841
- c2 = 7392488009685177703766329111985085924328495872306844961776805115046085005730
- n3 = 51501476121983355743052534942567218556170618226963749616587274414221577824191
- c3 = 21070202880950860480001393449893080177749578386435659153510821967923393222435
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def crt(c, n):
total = 0
ret = 1
for n_i in n:
ret *= n_i
for c_i, n_i in zip(c, n):
p = ret // n_i
total += c_i * gmpy2.invert(p, n_i) * p
return total % ret
n = [n1, n2, n3]
c = [c1, c2, c3]
x = crt(c, n)
m = gmpy2.iroot(x, e)[0]
print(long_to_bytes(m))
# utflag{wh0_1s_h45t4d}
Using the script above, we have successfully recovered the plaintext.
During CTF, you should consider this attack if there are:
Multiple Encryptions: A situation where the same plaintext has been encrypted multiple times.
Same Public Exponent (e): Each encryption uses the same public exponent e.
Different Moduli (n’s): Each encryption uses a different modulus n.
Small Exponent (e): The public exponent e is relatively small (commonly 3 or 5 in such scenarios).
Number of Ciphertexts: The number of available ciphertexts is at least equal to e (eg: i >= e).
Weiner's Attack
Wiener’s Attack targets RSA systems that use a small private exponent d relative to the modulus n. The attack is feasible when the private exponent d is smaller than approximately d < ⅓ n¼ and the public exponent e and the modulus n must satisfy the condition ed = 1 + kφ(n), where φ(n) is Euler’s totient function and k is some integer.
Wiener’s Attack leverages the fact that the fraction e/N can be expressed as a continued fraction. By finding the convergents of the continued fraction of e/N, you can approxiate k/d.
From the convergents, you can efficiently derive k and d to recover the private key.
Hence, if you notice that the public key e is very large compared to the modulus n, this might indicate that the private key d is small. In such a case, Wiener’s Attack is a viable method to recover d. You can apply existing implementations or scripts to perform the attack, such as the one available on GitHub at rsa-wiener-attack.
Block Ciphers in CTF
Block ciphers are the basics to modern encryption techniques. In cryptography, a Block Cipher (also known as Block Encryption) is a symmetric cryptographic algorithm that divides plaintext into equal-sized blocks and encrypts or decrypts each block separately using a deterministic algorithm and a symmetric key.
Some definitions for the common keywords:
Mode of Operation: The method by which a block cipher is applied to data that exceeds the size of a single block. Different modes of operation handle how blocks are encrypted or decrypted to ensure that larger datasets can be securely processed.
Initialization Vector (IV): A sequence of bytes used to introduce randomness into the encryption process to ensure that even if the same plaintext is encrypted multiple times with the same key, the resulting ciphertext will be different.
Starting Variable (SV): Similar to the Initialization Vector, the Starting Variable is used during the encryption of the first block to provide a random seed.
Padding: A technique used to ensure that the data aligns with the block size required by the cipher. Padding is added to the last block if the data does not naturally fit the block size to ensure that the final block is of the correct length for encryption.
ECB
Electronic Code Book (ECB) is a basic mode of operation for block ciphers where each block of plaintext is encrypted independently to produce the ciphertext.
- Encryption:
- The plaintext is divided into blocks of a fixed size (typically 128 bits for AES).
- Each block is encrypted separately using the encryption algorithm
Eand the same key. - If the length of the plaintext is not a multiple of the block size, padding is added to the final block to make it fit the required size.
- For a plaintext block Pi, the ciphertext block Ci is:
- Decryption:
- Each ciphertext block is decrypted independently using the decryption algorithm
Dand the same key used during encryption. - For a ciphertext block Ci, the plaintext block Pi is recovered by:
- Each ciphertext block is decrypted independently using the decryption algorithm
Due to this, ECB is straightforward to implement since each block is treated independently. This causes a drawback of ECB is that identical plaintext blocks will result in identical ciphertext blocks. This means patterns in the plaintext (like repeated data) will be visible in the ciphertext, which can leak information to an attacker.
CBC
Cipher Block Chaining (CBC) mode improves upon the weaknesses of ECB by introducing a dependency between each block of plaintext and the preceding ciphertext block. This creates a stronger link between blocks which hides patterns better.
To start the encryption process:
- The first block of plaintext is XORed with a random
IV. The IV is a random value that ensures that even if the same plaintext is encrypted multiple times, the ciphertext will be different each time. - Each subsequent plaintext block is
XORedwith the previous ciphertext block before being encrypted. This creates a dependency where each ciphertext block depends on the current plaintext block and all preceding blocks.
Equation for encrypting the first block is:
\[C_0 = E(P_0) \oplus IV)\]For subsequent blocks will be:
\[C_i = E(P_i \oplus C_{i-1})\]Where:
- Ci is the ciphertext block.
- Pi is the plaintext block.
- ⊕ denotes the XOR operation.
- E is the encryption algorithm.
To decrypt it:
- each ciphertext block is first decrypted and then the result is
XORedwith thepreviousciphertext block to recover the plaintext. - The
IVis used to decrypt the first block of ciphertext.
Equation for decrypting the first block is:
\[P_0 = D(C_0) \oplus IV)\]For subsequent blocks will be:
\[P_i = D(C_i) \oplus (C_{i-1})\]Where the D is the decryption algorithm.
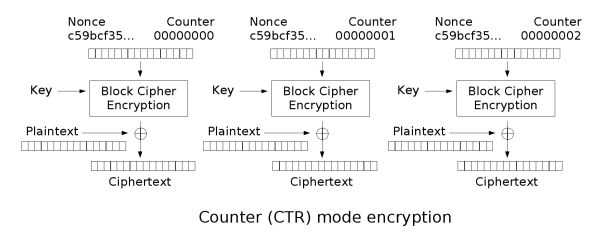
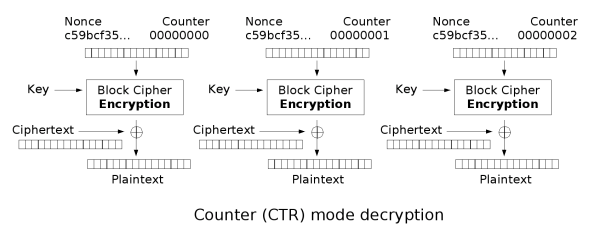
CTR (Counter) Mode
CTR (Counter) mode is a mode of operation for block ciphers that transforms them into stream ciphers. In CTR mode, a counter value is combined with a nonce (which is similar to an IV) and a key to generate a keystream. This keystream is then XORed with the plaintext to produce the ciphertext.
During decryption, the same keystream is XORed with the ciphertext to get the plaintext. One of the key advantages of CTR mode is that it allows for parallel processing as the counter value for any block is easy to compute which makes it possible to start encryption or decryption from any block. This random access property is particularly useful for applications requiring efficiency and flexibility. Additionally, using a counter that ensures unique outputs (no repeated values) is crucial for maintaining the security of the encrypted data as it ensures that identical plaintext blocks do not produce the same ciphertext blocks.
OFB Mode
Output Feedback (OFB) mode is a method used to transform a block cipher into a stream cipher. In OFB mode, the encryption process is initiated by encrypting an IV with the block cipher using the encryption key. This encrypted IV becomes the first output block, Y0, which is then XORed with the first block of plaintext P1 to produce the first block of ciphertext C1.
Decryption in OFB mode is identical to encryption due to the symmetry of the XOR operation. The ciphertext block Ci is XORed with the corresponding output block Yi to get the plaintext block Pi.
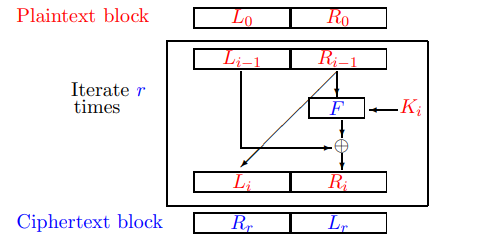
Feistel Ciphers
The Feistel Cipher is a fundamental cryptographic structure used in many block ciphers, including DES. The interesting property of a Feistel cipher is that the round function F does not need to be reversible, which simplifies the design while still ensuring that the entire encryption process can be inverted during decryption using the secret key.
Feistel Cipher works as follow:
- Division into Halves
- The plaintext block is divided into two equal halves (L0 for left half and R0 for right half).
- Encryption
- In each round
i, the following operations are performed:
- We can also write it as:
- In each round
- Decryption
- applying the same structure but with the round keys Ki used in reverse order.
- We can also write it as:
DES
DES is a block cipher meaning it encrypts data in fixed-size blocks. Specifically, it operates on 64-bit blocks of plaintext which are transformed into 64-bit blocks of ciphertext through a series of complex operations. The key used in DES is 56 bits long, although the full key size is technically 64 bits where the remaining 8 of these bits are used for parity and are not part of the actual encryption process.
You may read more about it here.